概览
项目当前仍在开发中,不可避免会存在较多 bug,欢迎大家提交 Issue 和 PR,共同推进项目的发展。
AgentGuard 是一个面向 AI 智能体工具调用场景的运行时访问控制项目。它位于智能体与实际工具之间,在工具执行前依据预设策略对当前操作进行检查,并给出相应处理结果。
当智能体具备以下能力时,AgentGuard 的价值会比较明显:
- 发送邮件
- 访问外部网络
- 执行命令
- 读写文件
- 访问数据库
这类能力通常意味着更高的安全风险。AgentGuard 的主要作用,就是在这些操作真正发生前建立一层可配置的控制机制。
项目定位
AgentGuard 关注的不是如何构建智能体本身,而是如何为智能体的工具使用建立治理能力。它适合用于回答下面几类问题:
- 哪些工具可以被调用,哪些不可以
- 哪些目标地址、邮箱或路径是允许的
- 哪些数据不应被外发
- 哪些操作需要人工确认
- 智能体实际执行过哪些高风险动作
因此,AgentGuard 更适合作为智能体系统中的安全控制层,而不是业务编排层。
主要能力
当前版本面向用户最重要的能力包括:
- 对工具调用进行允许或拒绝
- 对不确定但高风险的操作引入人工审批
- 对关键操作进行审计记录
- 基于任务上下文和调用过程做规则判断
在实际使用中,常见配置方式包括:
- 禁止低信任智能体执行危险命令
- 限制敏感数据发送到外部邮箱或外部网站
适用场景
如果智能体仅用于对话,且不会调用任何外部工具,通常没有引入 AgentGuard 的必要。
如果智能体已经能够接触真实系统资源,则建议考虑接入,尤其适用于以下场景:
- 办公自动化助手
- 具备系统操作能力的自动化 Agent
- 多团队共享的智能体平台
- 需要将安全规则与业务代码分离管理的项目
基本工作方式
从使用角度看,AgentGuard 的工作流程可以概括为:
- 用户先定义智能体及其可用工具
- 将 AgentGuard 接入智能体运行过程
- 编写访问控制策略
- 智能体发起工具调用时,先由 AgentGuard 检查
- AgentGuard 根据策略决定后续处理方式
换句话说,AgentGuard 不替代智能体执行任务,而是在智能体执行高风险操作前提供统一的判定与约束能力。
AgentGuard 设计架构
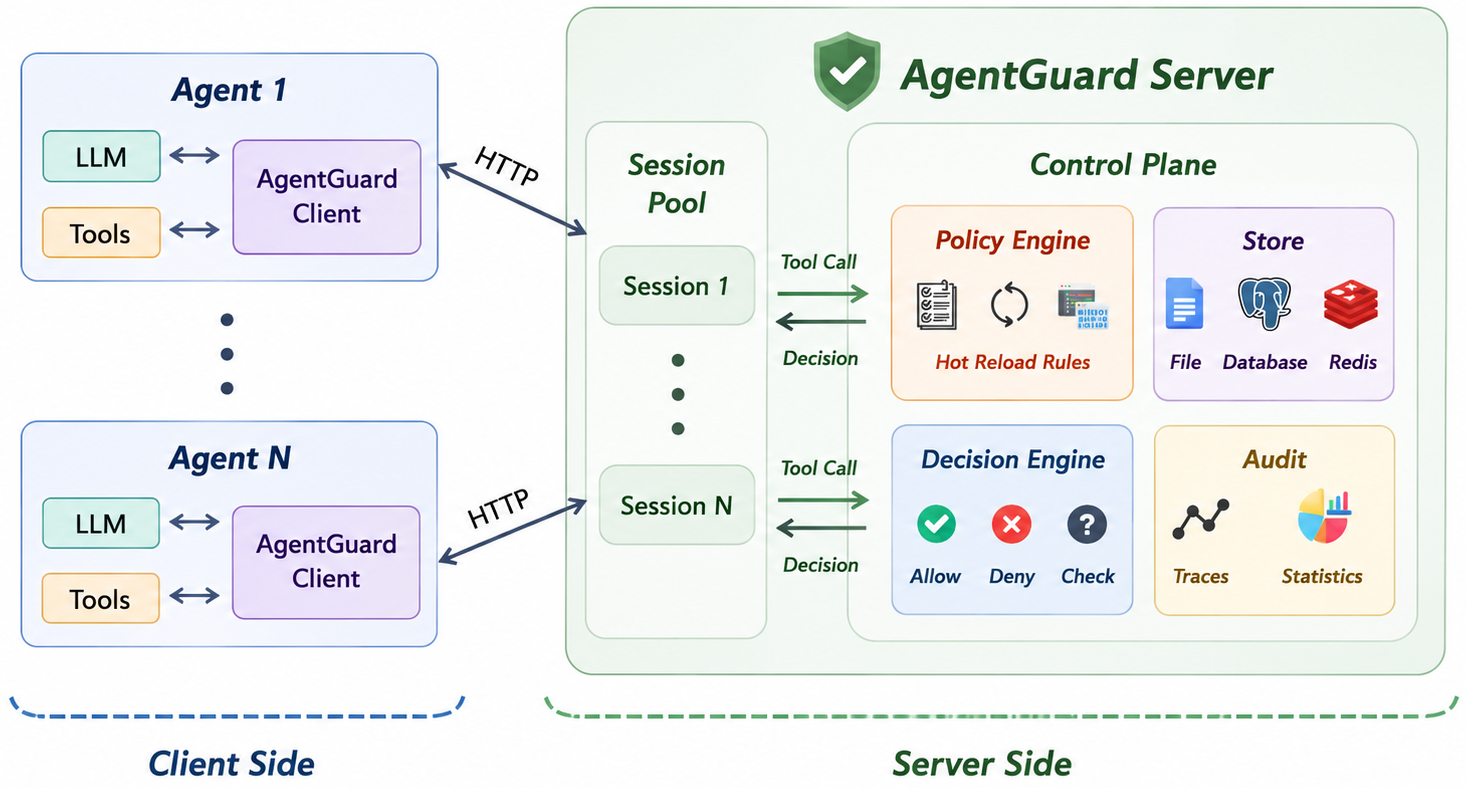
使用时应重点关注的内容
对于大多数用户而言,接入 AgentGuard 时最重要的不是内部实现,而是以下几个方面。
工具边界
首先应明确智能体实际具备哪些工具能力,尤其是以下高风险类别:
- 外发类工具
- 系统命令类工具
- 文件写入类工具
- 数据库写入类工具
- 内部数据读取类工具
这些通常是优先配置策略的对象。
禁止项
应明确哪些行为属于绝对不允许发生的操作,例如:
- 将内部数据发送到外部目标
- 执行危险系统命令
- 修改关键系统文件或生产数据库
这类要求通常适合配置为直接拒绝。
审批项
对于无法简单归类为“安全”或“危险”的操作,可以引入人工审批机制作为补充控制。
当前版本更适合处理的问题
从当前实现来看,AgentGuard 最适合用于工具调用治理场景,尤其包括:
- 邮件外发控制
- HTTP 外发控制
- Shell、文件系统与数据库访问控制
- 基于任务过程的规则判断
- 审计与人工审批
如果你的目标是为智能体的工具使用建立明确、可配置、可审计的约束机制,当前版本已经具备较清晰的支持。